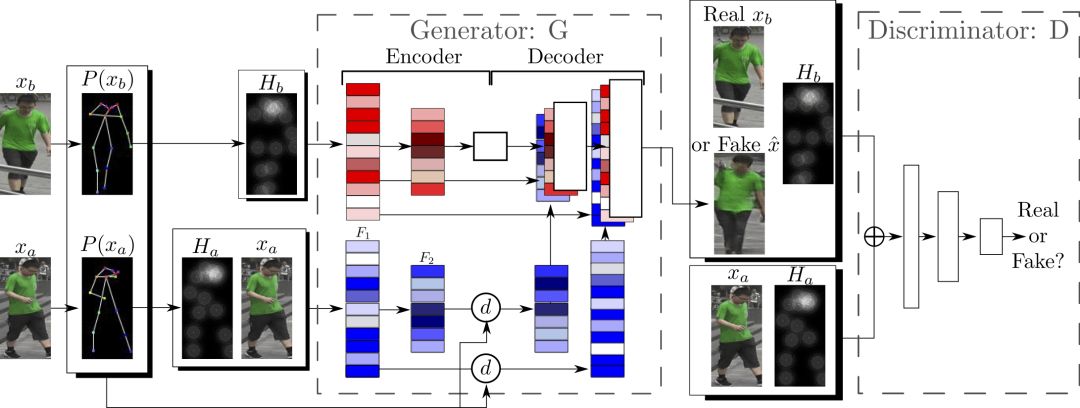
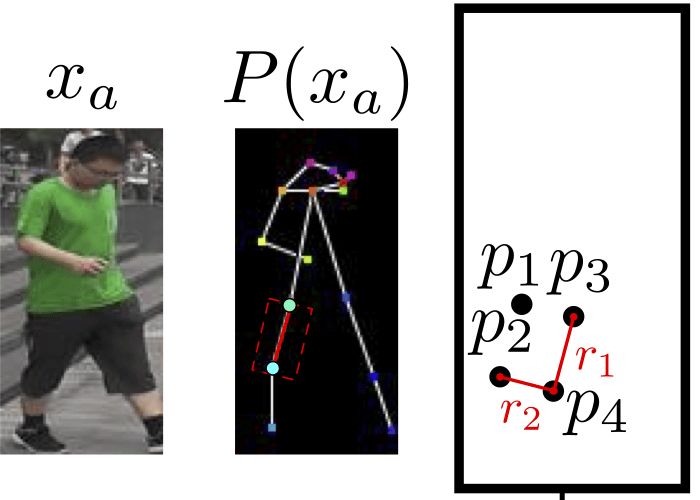
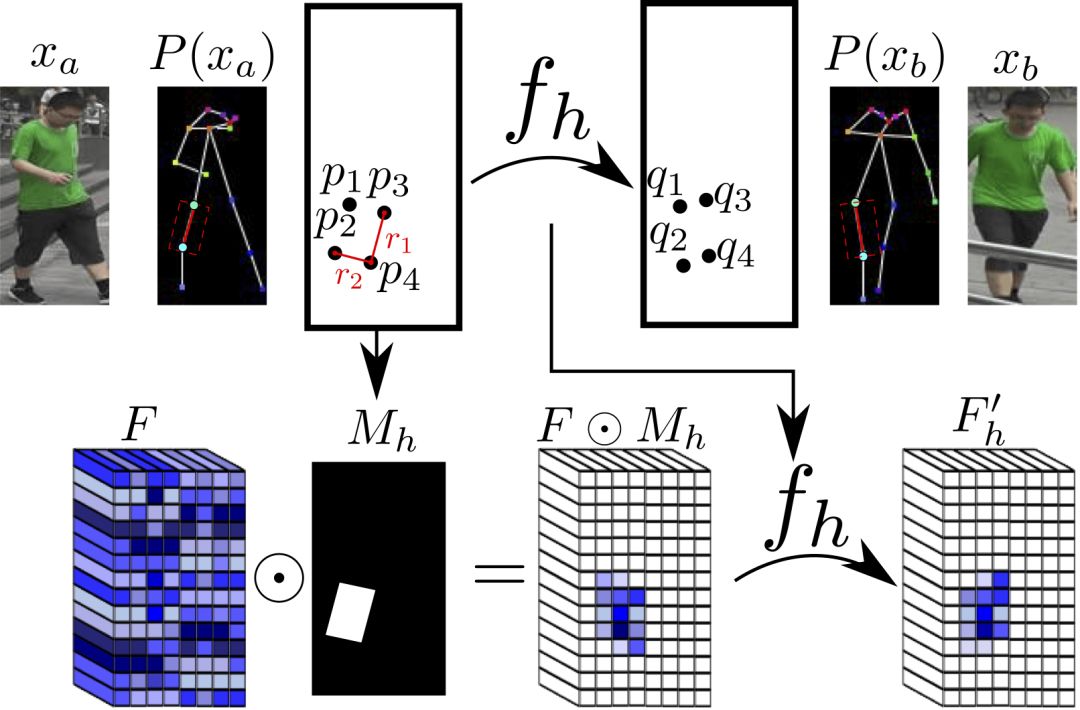
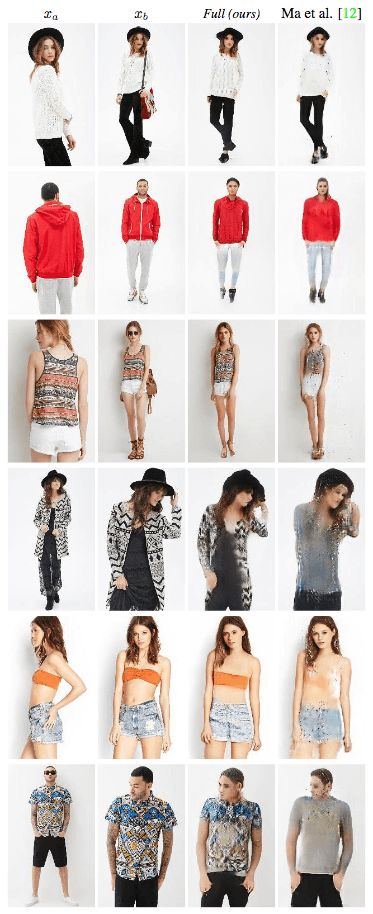
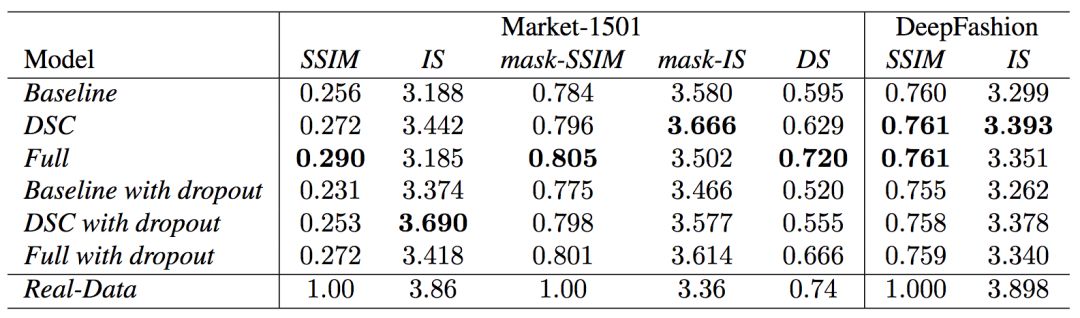
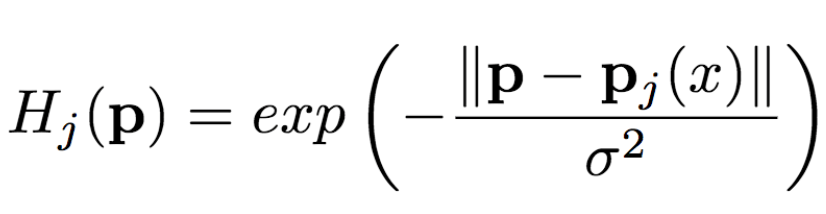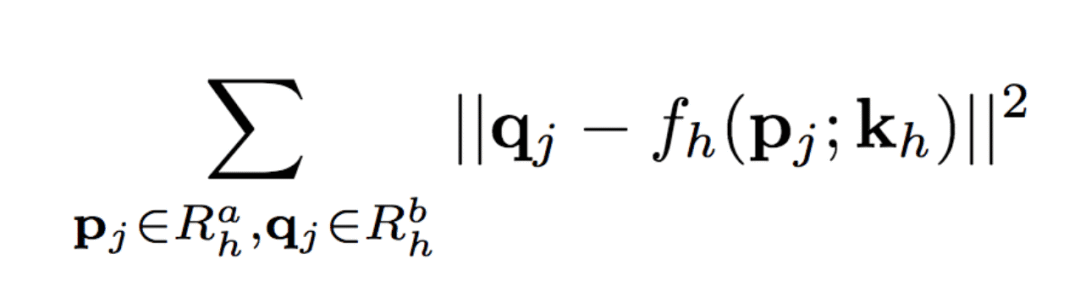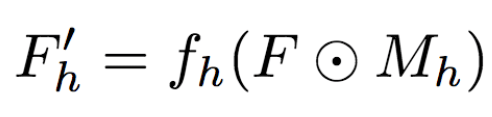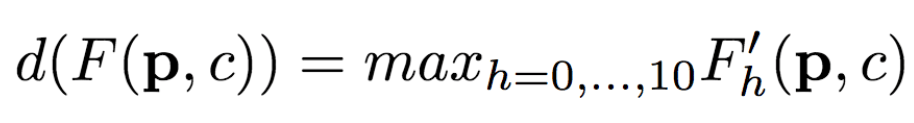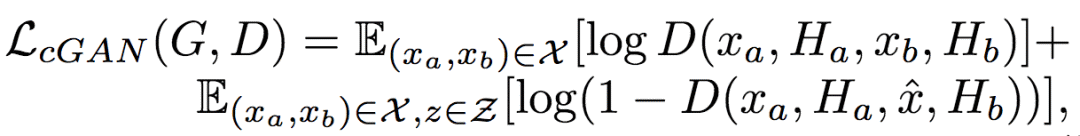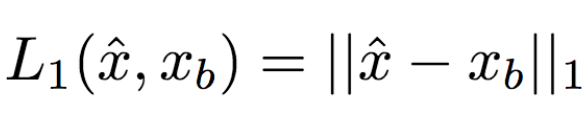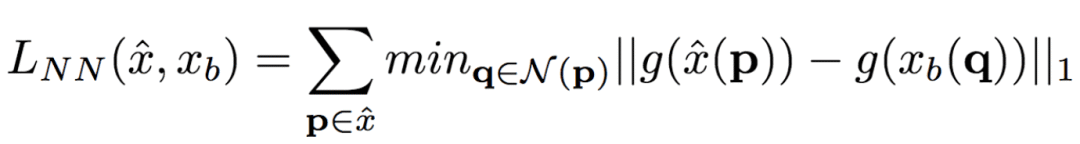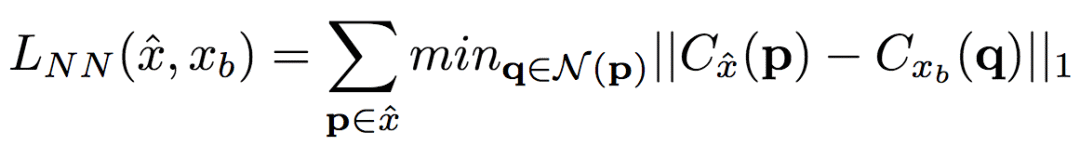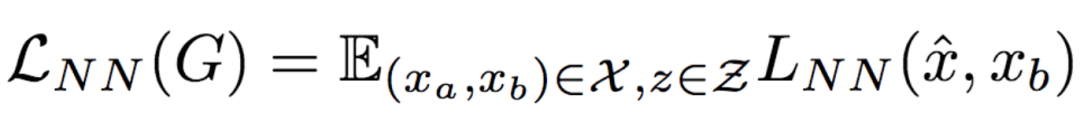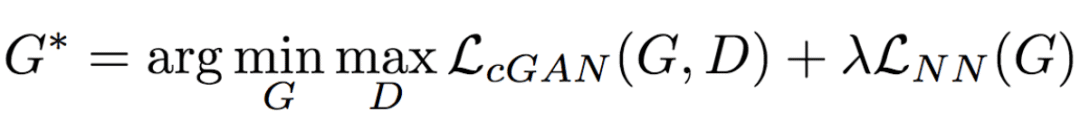The University of Trento, Italy, and the researchers of the French National Institute of Computer and Automation (Aliaksandr Siarohin, Enver Sangineto, Stephane Lathuiliere, Nicu Sebe) collaborated to generate new pose images of the human body using GAN (against generation networks). The researchers proposed the deformable jump connection and the nearest neighbor loss function to better capture the local texture details, alleviate the problem of image blur generated by previous research, and generate more reliable and better quality images. Network Architecture A deep learning method for generating visual content, the most commonly used is the Variational Automated Encoder (VAE) and the Generated Confrontation Network (GAN). The VAE is based on a probability map model and is trained by maximizing the lower bound of the likelihood of the corresponding data. The GAN model is based on two networks: a generation network and a discriminant network. The two networks train at the same time, the generation network tries to "fool" the discriminating network, and the discriminating network learns how to distinguish between real images and false images. Most of the work on posture generation is based on conditional GAN, where researchers also use conditional GAN. Some previous work used a two-stage approach: the first phase for posture integration and the second phase for image improvement. Researchers use an end-to-end approach. Since GAN is used, the design of the network architecture consists of two parts, generating the network and discriminating the network. Among them, in general, the design of the discriminant network is relatively easy. This is intuitive, for example, it is much easier to discriminate between the true and false of the painting than to make a fake that is enough to be fake. Therefore, we first consider the situation of the network. Discriminant network We consider discriminating the input and output of the network. The first is a relatively simple output. Discriminating the output of the network is basically two kinds, one is the discrete classification result, true or false, and the other is a continuous scalar, indicating the confidence that the network is true for the image. Here the researchers chose the latter as the output of the discriminant network. The simplest case of discriminating the input of a network is to accept an image, which may be a real image, or an image that is forged by the network (ie, the output of the generated network). However, specific to this particular problem, generating a new pose image of the same character from the original image, then the model can also provide some additional information to the discriminant network to help determine the authenticity of the network judgment image. The first image that can be provided is the original image. Secondly, it is related posture information, specifically, posture information extracted from the original image, and target posture information. Therefore, it is actually discriminated that the input accepted by the network is a tuple (xa, Ha, y, Hb) composed of four tensors. Where xa is the tensor representing the original image, and Ha and Hb respectively represent the posture and target posture of the original image. y is the real image (xb) or the output of the generated network. As mentioned above, the work of discriminating the network is relatively simple. Therefore, the input layer of the discriminating network does not specifically handle the tuples composed of the four tensors, and the concatenate is sufficient. Generating network As mentioned earlier, the design of the generated network requires a little more thought. Similarly, we first consider the output of the generated network. It is very simple. The output of the generated network is the image. Specifically, it is a tensor that represents the image. So what is the input to generate the network? In fact, it is very simple. From discriminating the input of the network, it is not difficult for us to get the input of the generated network. Discriminating the input of the network, as we mentioned earlier, is a tuple of four tensors (xa, Ha, y, Hb). Among them, this y is generated by the generation network, so we remove y and get (xa, Ha, Hb). This is almost as an input to the generation network. It is instinctive to generate similarities between the input network and the discriminant network. Information that helps to distinguish the true and false images also helps to fake false images. However, there are some noises in the image. Therefore, in order to deal with the noise problem of the data samples, in order to better learn the technique of realism, the generation network additionally accepts a noise vector z as an input. Therefore, the input to the generated network is (z, xa, Ha, Hb). Discrimination of the network is not a matter of noise, this is because it is much easier to judge the work of the network, isn't it? It is determined that the input of the network is directly connected, and the network is generated. Because the tasks faced are much more difficult, it is not directly connected to xa, Ha, and Hb. Because Ha is based on the posture information extracted by xa, there is consistency, or tight connection, between the two. Hb is the target posture, and the relationship with xa and Ha is not so close. Therefore, it is better to handle it separately. The researchers did this by concatenating xa and Ha, using one convolution stream of the encoder, and Hb using another convolution stream, with no weight sharing between the two. Representation of posture Above we mentioned Ha and Hb, which is the posture information, but how are these posture information represented? The easiest way to express a pose is to find the joints (abstract into points), then join the joints (lines) and use the dotted line combination (joint position) to represent the pose. After extracting the pose (joint position) from the image, it also needs to be converted into a form that the generation network can understand. Previous work has found that the use of heat maps works well, and researchers here also use heat maps to represent postures. That is, if we use P(xa) to represent the pose extracted from x (P is pose, the first letter of the pose), then Ha = H(P(xa)) (H is the heat map, the first letter of the heat map) ). Among them, Ha is composed of k heat maps, and Hj (1<=j<=k) is a two-dimensional matrix whose dimensions are consistent with the original image. The heat map and joint position satisfy the following relationship: Where pj is the jth joint position and σ = 6 pixels. The entire network architecture is shown below: Deformable jump connection The change of posture can be seen as a problem of spatial deformation. A common idea is to encode the associated deformation information by the encoder, which then restores the encoded deformation information. The network architecture consisting of an encoder and a decoder is commonly used as U-Net. Therefore, some previous studies have widely used U-Net-based methods to perform gesture-based portrait image generation tasks. However, ordinary U-Net jump connections are not suitable for large spatial deformations because local information of the input image and the output image are not aligned in the case of large spatial distortion. Since the larger spatial deformation has the problem of local information misalignment, the spatial deformation is split into different parts so that each part is aligned. Based on the above ideas, the researchers proposed a deformable skip connection, which decomposes the global deformation into a set of local affine transformations defined by a subset of joints, and then combines these local affine transformations to approximate the global Deformation. Decompose the human body As mentioned earlier, local affine transformations are defined by a subset of joints. Therefore, we must first divide the subset of joints, that is, decompose the human body. The researchers broke down the body into 10 parts, head, torso, left upper arm, right upper arm, left forearm, right forearm, left thigh, left calf, right thigh, right calf. The division of specific blocks in each section is based on joints. The definition of the head and torso is simple. Just align the axis and draw a rectangle that encloses all the joints. The situation of the limbs is more complicated. The limbs consist of two joints, and the researchers used a slanted rectangle to divide the limbs. One side of the rectangle, r1, is a line parallel to the joint line, and the other side, r2 and r1, is perpendicular, and the length is equal to one-third of the mean value of the torso of the torso (this value is used uniformly). Then we get a rectangle. The picture above is an example. We can express the segmented area as Rha = {p1, ..., p4}. Where R represents the region (the first letter of the region), h indicates that this is the h-th region of the human body, a indicates that the region belongs to the image xa, and p1 to p4 are the four vertices of the region rectangle. Note that these are not joints. Affine transformation Then, we can calculate the binary mask Mh(p) of Rha, except for the points in Rha, the values ​​of the other positions are all zero. Similarly, Rhb = {q1, ..., q4} is the corresponding rectangular local area in image xb. Matching the points in Rha and Rhb, you can calculate the six parameters kh of this part of the affine transformation fh: The parameter vector kh of the above affine transformation is calculated based on the resolution of the original image, and then the corresponding version is respectively calculated according to the specific resolution of the different convolution feature maps. Similarly, versions of different resolutions of each binary mask Mh can be calculated. In the actual image, the corresponding area may be obscured by other parts, or outside the frame of the image, or may not be successfully detected. For this case, the researchers directly set Mh to a matrix with all element values ​​of 0, without calculating fh. (In fact, when the missing area is a limb, if the symmetrical body part is not missing, for example, the right upper arm is missing, and the left upper arm is successfully detected, then the information of the symmetrical part can be copied.) For each pair of real images (xa, xb) in the dataset, (fh(), Mh) and its lower resolution variants need only be calculated once. In addition, this is the only part of the entire model that is related to the human body. Therefore, the entire model can be easily extended to solve the task of generating other deformable objects. Affine transformation diagram Combined affine transformation Once the (fh(), Mh) of each region of the human body is calculated, these local affine transformations can be combined to approximate the global posture deformation. Specifically, the researchers first calculated based on each region: Then the researchers combined them: Among them, F'0 = F (undeformed), can provide texture information of the background point. Here, the researchers chose the maximum activation, and the researchers also tested the average pooling, and the average pooling effect was slightly worse. Nearest neighbor loss In addition to the standard conditional versus loss function LcGAN, the researchers used the nearest neighbor loss LNN when training the network and discriminating the network. The specific definition of LcGAN is: Among them, x with a hat is a generated image G(z, xa, Ha, Hb) of the generated network. In addition to the standard LcGAN, some previous studies used a loss function based on L1 or L2. For example, L1 calculates the pixel-to-pixel difference between the generated image and the real image: However, L1 and L2 can cause blurry images to be generated. The researchers suspect that the reason may be that these two types of loss functions cannot accommodate the small spatial misalignment between the generated image and the real image. For example, suppose the image generated by the generated network looks very reliable and semantically similar to the real image, but the pixels of the texture details on the two image costumes are not aligned. Both L1 and L2 will punish such inaccurate pixel-level alignment, although in humans these are not important. To alleviate this problem, the researchers proposed a new nearest neighbor LNN: Where N(p) is the nxn local neighbor of point p. g(x(p)) is a vector representation of the patch near point p, and g(x(p)) is derived from the convolution filter. The researchers compare the generated patch representation (g()) between the image and the real image to efficiently calculate the LNN. Specifically, the researchers selected the second convolutional layer (conv12) of VGG-19 trained on ImageNet. The convolution span of the first two convolutional layers (conv11 and conv12) of VGG-19 is 1, so the feature map Cx of image x in conv12 has the same resolution as the original image x. Using this fact, the researchers were able to directly calculate nearest neighbors on conv1_2 without compromising spatial accuracy, ie g(x(p)) = Cx(p). According to this, the definition of LNN becomes: The researchers finally optimized the implementation of the above LNN to enable parallel operations on the GPU. Therefore, the final LNN-based loss function is defined as: Combine the above formula with LcGAN to get the objective function: The researchers set the value of λ in the above equation to 0.01, and λ acts as a regularization factor. Implementation details When training the generation network and discriminating the network, the researchers used 90,000 iterations and used Adam optimization (learning rate: 2x10-4, β1 = 0.5, β2 = 0.999). As mentioned earlier, the encoder portion of the generated network contains two streams, each consisting of a sequence of layers: CN641 - CN1282 - CN2562 - CN5122 - CN5122 - CN5122 Among them, CN641 represents the use of instance normalization, ReLU activation, 64 filters, convolution layer with span of 1, followed by the same. The decoder portion of the corresponding generated network consists of the following sequence: CD5122 - CD5122 - CD5122 - CN5122 - CN1282 - CN31 Among them, CD5122 is similar to CN5122, except that an additional 50% dropout is added. In addition, the last convolutional layer has no application instance normalization, and uses tanh instead of ReLU as the activation function. The discriminant network uses the following sequence: CN642 - CN1282 - CN2562 - CN5122 - CN12 Among them, the last convolutional layer has no application instance normalization, and uses sigmoid instead of ReLU as the activation function. The encoder and decoder used to generate the network for the DeepFashion dataset (one of the data sets used by the researchers, see the next section) uses an additional convolutional layer (CN5122) because the images in the dataset have higher Resolution. test data set The researchers used two data sets: Market-1501 DeepFashion The Market-1501 contains 32,668 images of 1501 people shot with six surveillance cameras. This data set is challenging due to the low resolution of the image (128x64) and the variety of poses, Lighting, background and perspective. The researchers first removed the image of the undetected human body and obtained 263,631 pairs of training images (a pair of images of different pose images of the same person). The researchers randomly selected 12,000 pairs of images as test sets. DeepFashion contains 52,712 costume images with 200,000 pairs of images of the same costume, different poses or sizes. The resolution of the image is 256x256. The researchers selected the same person to wear the same clothing but different posture pairs, of which, randomly selected 1000 kinds of clothing as a test set, the remaining 12029 kinds of clothing as a training set. After removing images of undetected humans, the researchers eventually collected 101,268 pairs of images as training sets and 8670 pairs of images as test sets. Quantitative assessment Quantitative assessment of the generated content itself is a problem under study. Two metrics appear in the current research literature: SSIM (Structural Similarity) and IS (Inception Score). However, there is only one object classification (human) in the gesture generation task, and the IS index is based on the entropy value calculated by the classification neuron of the external classifier, so the two are not very compatible. In fact, the researchers found that the correlation between the IS value and the quality of the generated image is often weak. Therefore, the researchers proposed an additional DS (Detection Score) indicator. DS is based on the detection output of the most advanced object detection model SSD, which is trained based on the Pascal VOC 07 data set. This means that DS measures the authenticity of the generated image (how much like a person). On the current state-of-the-art model, the model used by the researchers, the real image As you can see, overall, the performance of the model exceeds the current state of the art model. In addition, note that the DS value of the real image is not 1, because the SSD cannot detect the human body 100%. Qualitative assessment The researchers also conducted a qualitative assessment. It can be clearly seen that the model significantly reduces the degree of blurring of the generated image due to the LNN-based loss function. The qualitative assessment results on DeepFashion are similar. Ablation test To validate the validity of the model, the researchers also performed qualitative and quantitative ablation tests. Market-1501 The figure above shows the qualitative ablation test performed on the Market-1501 data set. Columns 1, 2, and 3 represent the input to the model. Column 4 is a real image. The fifth column is the reference output (the U-Net architecture does not use the deformable jump connection. In addition, in the generation network, xa, Ha, and Hb are directly connected as inputs, that is, the encoder that generates the network contains only one stream, and the training network The L1-based loss function is used, the sixth column DSC is a model trained using the L1-based loss function, and the seventh column Full is the complete model. It can be seen that the images generated by the researchers' proposed models look more realistic and retain more texture details. The researchers achieved similar results on DeepFashion. The researchers also performed quantitative ablation tests and additionally experimented with the effects of dropout (generating the network and discriminating the network while applying dropout). Solar home energy storage power supply SHENZHEN CHONDEKUAI TECHNOLOGY CO.LTD , https://www.szsiheyi.com